
각진 세상에 둥근 춤을 추자
[Python] 네이버 뉴스 크롤링 + 엑셀 저장 본문
이전 글 참고
2023.01.18 - [Python] - [Python] 크롤링 HTML 페이지 요청하기
[Python] 크롤링 HTML 페이지 요청하기
1. 모듈 설치 pip install requests pip install bs4 설치 후, 본문 맨 윗 부분에 import문 작성 import requests as req from bs4 import BeautifulSoup as bs [ERROR] zsh: command not found: pip → 참고 [Error] - [Python] pip install ~ 에러 [P
this-circle-jeong.tistory.com
앞서 html 페이지 요청 크롤링을 토대로 네이버 뉴스 크롤링을 실습해 본다.

1. 모듈 설치
pip install requests
pip install bs4
pip install openpyxl
위 모듈을 설치 후 또는 이미 설치되어 있다면 본문 맨 윗부분에 import한다.
import requests as req
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
2. 엑셀 파일 생성
workbook = Workbook()
sheet = workbook.activepg = 1
count = 1
while True:
# 페이지 (HTML) 요청
url = 'https://news.naver.com/main/list.naver?mode=LS2D&sid2=230&sid1=105&mid=shm&page=%d' % pg
html = req.get(url, headers= {'User-Agent':'Mozilla/5.0'}).text(Mozila/5.0 은 크롬의 User-Agent 값이다.)
# 문서 객체 생성
dom = bs(html, 'html.parser')
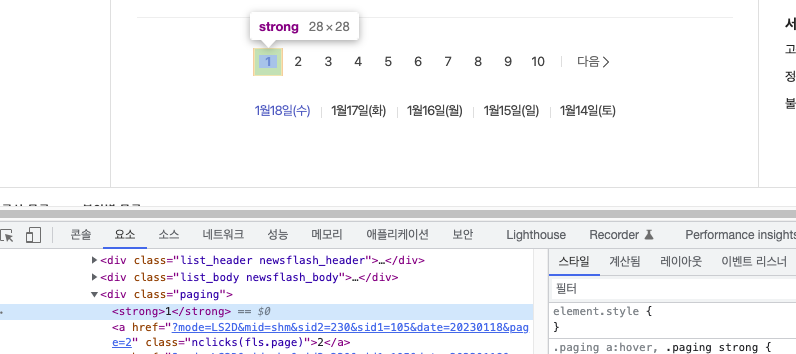
currentPage = dom.select_one('#main_content > div.paging > strong').text
if pg != int(currentPage):
break(currentPage에는 현재 페이지 값의 셀렉터를 복사해 주었다.)
# 데이터 파싱
tit = dom.select_one('#main_content > div.list_header.newsflash_header > h3').text
lis = dom.select('#main_content > div.list_body.newsflash_body > ul > li')
for li in lis:
tag_a = li.select_one('dl > dt:not(.photo) > a') # 클래스가 photo가 아닌 dt 선택
title = tag_a.text
href = tag_a['href']
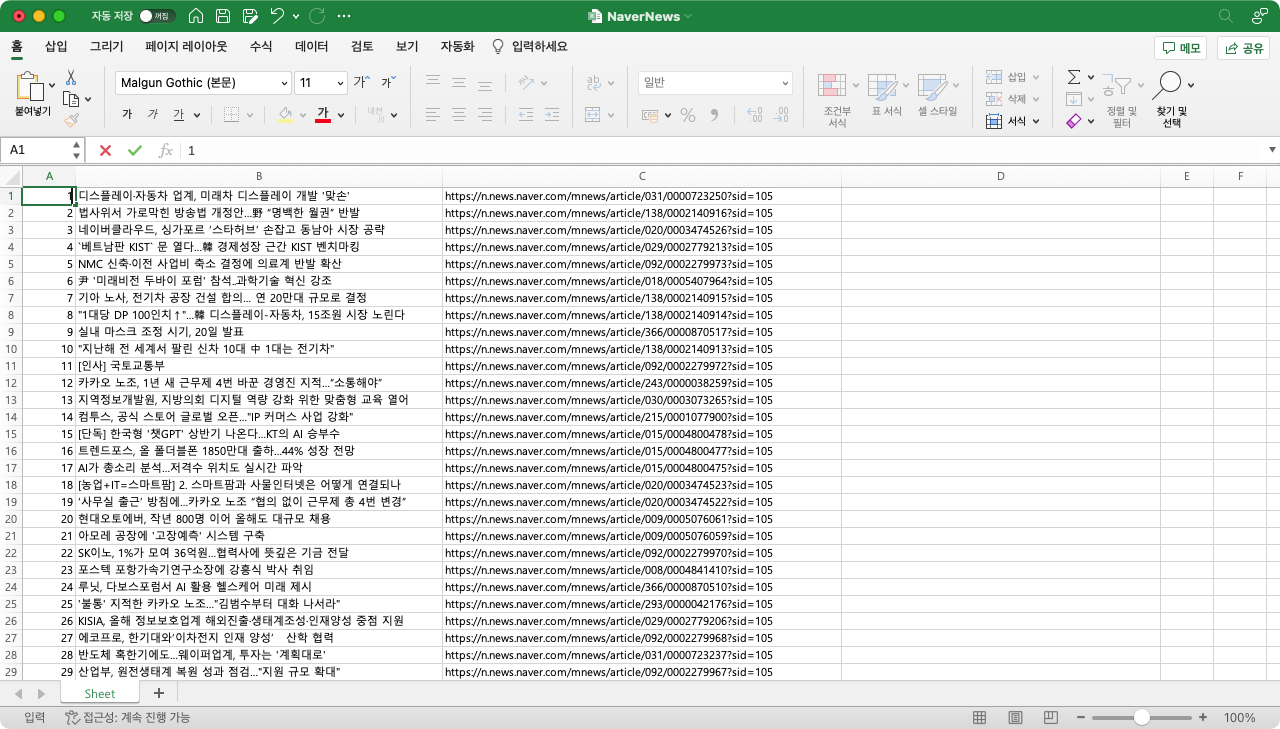
sheet.append([count, title.strip(), href.strip()])
count += 1
pg += 1(tit: 기사 제목, lis: 리스트)
3. 엑셀 저장/종료
workbook.save('저장할 위치/NaverNews.xlsx')
workbook.close()
(예) 저장할 위치
- 윈도우: C:/Users/java2/Desktop/NaverNews.xlsx
- 맥: /Users/iilhwan/Desktop/NaverNews.xlsx
전체코드
더보기
"""
파이썬 네이버 뉴스 크롤링 실습하기
BeautifulSoup: 정적 페이지
"""
import requests as req
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
# 엑셀파일 생성
workbook = Workbook()
sheet = workbook.active
pg = 1
count = 1
while True:
# 페이지(html) 요청
url = 'https://news.naver.com/main/list.naver?mode=LS2D&sid2=230&sid1=105&mid=shm&page=%d' % pg
html = req.get(url, headers= {'User-Agent':'Mozilla/5.0'}).text
# print(html)
# 문서 객체 생성
dom = bs(html, 'html.parser')
currentPage = dom.select_one('#main_content > div.paging > strong').text
if pg != int(currentPage):
break
# 데이터 파싱
tit = dom.select_one('#main_content > div.list_header.newsflash_header > h3').text
print('tit: ', tit)
lis = dom.select('#main_content > div.list_body.newsflash_body > ul > li')
for li in lis:
tag_a = li.select_one('dl > dt:not(.photo) > a') # 클래스가 photo가 아닌 dt 선택
title = tag_a.text
href = tag_a['href']
sheet.append([count, title.strip(), href.strip()])
print('%d건...', count)
#print('count: ', count)
#print('title: ', title.strip())
#print('href: ',href.strip())
count += 1
pg += 1
# 엑셀 저장/종료
workbook.save('/Users/iilhwan/Desktop/NaverNews.xlsx')
workbook.close()
print('프로그램 종료...')
'Python' 카테고리의 다른 글
| [Python] 가상 브라우저 크롤링 실습 (네이버 로그인) (0) | 2023.01.18 |
|---|---|
| [Python] 크롤링 HTML 페이지 요청하기 (0) | 2023.01.18 |
| [Python] 파이썬 데이터베이스(DB) 연동 (0) | 2023.01.18 |
| [Python] 파이썬 리스트 함수 (0) | 2023.01.06 |
| [Python] 파이썬 날짜시간, 수학, 랜덤함수 (0) | 2023.01.06 |
'Python' Related Articles
more


