
각진 세상에 둥근 춤을 추자
Kafka 단일 브로커 환경에서 고TPS 처리 구현 본문
지난 게시글:
Spring 기반 Kafka Producer-Consumer + Java 알람 매니저 (Kafka Streams 모듈화)로 실시간 알람 기능 구현
기존에는 카프카의 프로듀서와 컨슈머를 같은 서버에 두어 메시지를 전송 및 수신하였다. 2025.05.15 - [Java] - Kafka 로컬 설치 및 Spring Boot에서 Kafka 연동하기 File > Project Structure > Modules > Dependencies에
this-circle-jeong.tistory.com
이벤트를 발생시켜 데이터를 전송하는 역할인 스프링 기반의 웹 서버와 일반 자바 기반인 알람매니저를 구현했다.
이번에는 더 나아가 카프카 단일 브로커 환경에서 해당 웹 서버 혹은 이후에 추가될 클라이언트에서 초당 수십만 건의 이벤트가 발생하여 토픽에 전송될 경우의 상황을 가정하여 고TPS 환경을 설정해본다.
문제 요약
1. CPU와 메모리 병목
mapValues, objectMapper.readValue(), 조건 비교, 알람 전송 등은 CPU 연산이 많아지고, 객체 수십만 개가 쌓이면 GC 압박도 커진다.
2. 싱글 인스턴스 구조
KafkaStreams는 기본적으로 단일 JVM 인스턴스에서만 동작하면 멀티노드 확장이 안 됨. → 처리량 병목 발생.
3. EXACTLY_ONCE_V2 성능 손해
이 옵션은 안정성과 무결성 보장해주지만 → 내부적으로 트랜잭션 처리로 인해 throughput이 크게 감소함
🛠 해결 방향
1. FlatMap 사용
문제: mapValues → objectMapper.readValue() → 병목 요인이 될 수 있음.
해결: flatMap 사용해서 오류 방어성 향상 가능.
(1) MapValues
- 입력 하나 -> 출력 하나 (1:1 매핑)
- 즉 1개의 값 -> 1개의 결과
- null 반환이 가능 -> 그래서 null 체크를 하는 .filter() 과정이 필요
- "a" -> "A"
.mapValues(value -> {
return "변환된값"; // 항상 하나의 결과
})
(2) flatMapValues
- 입력 하나 -> 출력 0개 이상 (1:N 매핑)
- 즉 1개의 값 -> 0개, 1개, ... N개의 결과
- 반환값은 List<String> 또는 Iterable<T>
- "a" -> [A,B], "b" -> [ ]
.flatMapValues(value -> {
if (조건 만족) {
return List.of("하나의 결과"); // 1개 반환
} else {
return List.of(); // 아무것도 안 흘러감
}
})
AlarmManagerApp.java
현재 코드
.mapValues(value -> {
try {
// 처리
return JSON_STRING; // 조건 만족
} catch (...) { ... }
return null; // 조건 불만족 or 예외
})
.filter((key, value) -> value != null)// 5. event-topic 구독 (이벤트 수신)
KStream<String, String> eventStream = builder.stream("event-topic");
eventStream
.peek((key, value) -> log.warn("[이벤트 수신] key: " + key + ", value: " + value))
.mapValues(value -> {
try {
Map<String, Object> eventData = objectMapper.readValue(value, Map.class);
String metricKey = (String) eventData.get("type");
int count = Integer.parseInt(eventData.get("count").toString());
// 조건 비교
if(alarmConditions.containsKey(metricKey)){
AlarmCondition condition = alarmConditions.get(metricKey);
if (compare(count, condition.thresholdValue, condition.operator)) {
// 조건 충족 시 → 추가 필드 붙여서 알람 전송
eventData.put("severity", condition.severity);
eventData.put("category", condition.category);
log.warn("[알람 판단됨] metric_key: " + metricKey + ", count: " + count);
return objectMapper.writeValueAsString(eventData); // JSON 문자열로 다시 변환
}
}
} catch (Exception e) {
log.warn("event-message 파싱 실패: " + e.getMessage());
}
return null;
})
// 6. 조건 비교 결과에 따라 분기 조건 만족 시 → alarm-topic으로 전송
.filter((key, value) -> value != null)
.peek((key, value) -> log.warn("알람 전송 예정 → {}", value))
.to("alarm-topic"); // alarm-topic으로 전송- 조건 불만족하거나 에러 나면 -> null 리턴 -> .filter((key,value) -> value != null) 과정이 필요함
=> 불필요한 객체 흐름 발생
개선 코드
.flatMapValues(value -> {
try {
// 처리
return List.of(JSON_STRING); // 조건 만족
} catch (...) { ... }
return List.of(); // 조건 불만족 or 에러
})// 5. event-topic 구독 (이벤트 수신)
KStream<String, String> eventStream = builder.stream("event-topic");
eventStream
.peek((key, value) -> log.warn("[이벤트 수신] key: " + key + ", value: " + value))
.flatMapValues(value -> {
try {
Map<String, Object> eventData = objectMapper.readValue(value, Map.class);
String metricKey = (String) eventData.get("type");
int count = Integer.parseInt(eventData.get("count").toString());
// 조건 비교
if(alarmConditions.containsKey(metricKey)){
AlarmCondition condition = alarmConditions.get(metricKey);
if (compare(count, condition.thresholdValue, condition.operator)) {
// 조건 충족 시 → 추가 필드 붙여서 알람 전송
eventData.put("severity", condition.severity);
eventData.put("category", condition.category);
log.warn("[알람 판단됨] metric_key: " + metricKey + ", count: " + count);
return List.of(objectMapper.writeValueAsString(eventData)); // JSON 문자열로 다시 변환
}
}
} catch (Exception e) {
log.warn("event-message 파싱 실패: " + e.getMessage());
}
return List.of(); // 빈 리스트 반환
})
// 6. 조건 비교 결과에 따라 분기 조건 만족 시 → alarm-topic으로 전송
.peek((key, value) -> log.warn("알람 전송 예정 → {}", value))
.to("alarm-topic"); // alarm-topic으로 전송- 조건 만족 시 리스트 반환, 불만족 시 빈 리스트 반환 -> .filter 불필요
2. Kafka Batch 처리 - Micro Batch
문제: 기존의 Kafka Consumer와 Kafka Streams는 1건 씩 메시지를 처리한다.
(ex) 메시지 1건 처리 -> 다음 1건 처리 -> ... (메시지 10만 건 -> 10만 번의 I/O 발생)
해결: 배치 처리 (메시지를 여러 개 묶어서 한 번에 처리)
(ex) 메시지 10만 건 -> 100건 씩 묶어서 1천 번 처리
Q) 메시지를 묶어서 한 번에 처리하면 실시간성이 필요한 프로그램에서 부적합하지 않나?
A) 배치 처리와 실시간 처리는 반드시 충돌하지 않는다. 일정 수준까지 조율할 수 있다.
- 배치 처리 = 여러 메시지를 모아서 처리
- 실시간 처리 = 들어오는 즉시 바로 처리
| 전략 | 설명 | 실시간성 영향 |
| 작은 배치 사이즈 (max.poll.records=10~100) | 너무 많이 묶지 않고, 짧은 시간 안에 처리 | 실시간성 거의 유지됨 |
| 짧은 poll 간격 (commit interval = 1초 이내) | 자주 poll → 데이터 늦게 오지 않게 함 | 실시간 유지 |
| 타임 기반 배치 | 1초마다 들어온 걸 한꺼번에 처리 | "near-real-time" |
| 조건 기반 배치 | 100건 쌓이거나 1초 지나면 처리 | 성능 + 실시간성 균형 |
// commit 주기 짧게 - 1초 마다 커밋
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000);
// batch 처리 (메시지 묶어서 처리) - 한 번에 최대 100건 처리
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 100);=> Kafka Streams가 1초 단위, 최대 100건씩 처리하게 된다.
3. scale-out (스케일 아웃) -> 여러 개 띄우기
문제: 웹 이벤트 발생 시 event-topic으로 초당 수천~수만 건이 들어옴 -> alarm-manager 1개로는 처리가 버거움
해결: alarm-manager를 여러 개 띄운다.
Kafka의 기본 구조는 다음과 같다.

| 구성 요소 | 설명 |
| Topic | 메시지를 저장하는 공간 (예: event-topic) |
| Partition | Topic을 여러 조각으로 나눈 것 (scale-out 단위) |
| Consumer Group | 하나의 논리적인 소비자 집합 |
| Consumer | 실제 메시지를 처리하는 인스턴스 (우리의 alarm-manager) |
(1) event-topic을 여러 파티션으로 나눈다
(2) alarm-manaver를 여러 개 띄운다 (반드시 alarm-manager들을 같은 group.id로 묶는다)
=> 각 alarm-manager에 메시지를 자동으로 할당해 부하를 분산시킨다.
=> 각 alarm-manager는 중복 없이 서로 다른 메시지를 처리한다.
event-topic (3 partitions)
└─ alarm-manager-1 ⟶ partition 0
└─ alarm-manager-2 ⟶ partition 1
└─ alarm-manager-3 ⟶ partition 2
(1) event-topic 파티션 N개 만들기
파티션 수 결정 시 고려 요소
| 요소 | 설명 |
| Producer 수 | 동시에 메시지를 보내는 클라이언트 수 |
| Consumer 수 | 병렬로 메시지를 처리할 수 있는 worker 수 |
| 처리량 | 초당 메시지 수 (TPS: Transactions Per Second) |
| 시스템 자원 | CPU, RAM, 디스크 I/O 등 |
| 메시지 크기 | 평균 메시지 크기에 따라 처리 부하 다름 |
| 메시지 지연 허용치 | 실시간이냐, 약간의 지연이 가능하냐 |
추천 기준
| 상황 | 추천 파티션 수 |
| 테스트, 소규모 운영 | 1~3개 (병렬 처리 필요 없을 경우) |
| 1000 TPS 이하 | 3~6개 |
| 1만 TPS 이상 | 6~20개 |
| 10만 TPS 이상 또는 클러스터 기반 | 20개 이상+ 브로커 수 고려해서 복제와 분산 구성 필요 |
참고: 파티션 너무 많으면?
- 오버헤드 증가 (리밸런싱, 메타데이터 부하)
- 각 파티션마다 파일 핸들/스레드 사용되므로 브로커/OS 자원 많이 씀
- 메시지 순서 보장도 어려움
=> 메시지 양이 적은데 파티션만 많으면 낭비
=> 따라서 처음엔 6~12 개로 시작 -> TPS와 지연 확인 -> 필요 시 늘리기
(하지만 한 번 설정한 토픽의 파티션 수를 조절하면 기존 메시지 순서가 보장되지 않는 경우가 있기에
안전하게 토픽 삭제 후 재생성을 하는 것이 좋다.)
명령어로 생성
# topic name: event-topic
# partitions: 16
# replication-factor: 브로커 수가 1개인 경우 반드시 1
bin/kafka-topics.sh --create --topic event-topic \
--bootstrap-server localhost:9093 --partitions 16 --replication-factor 1
UI에서 생성
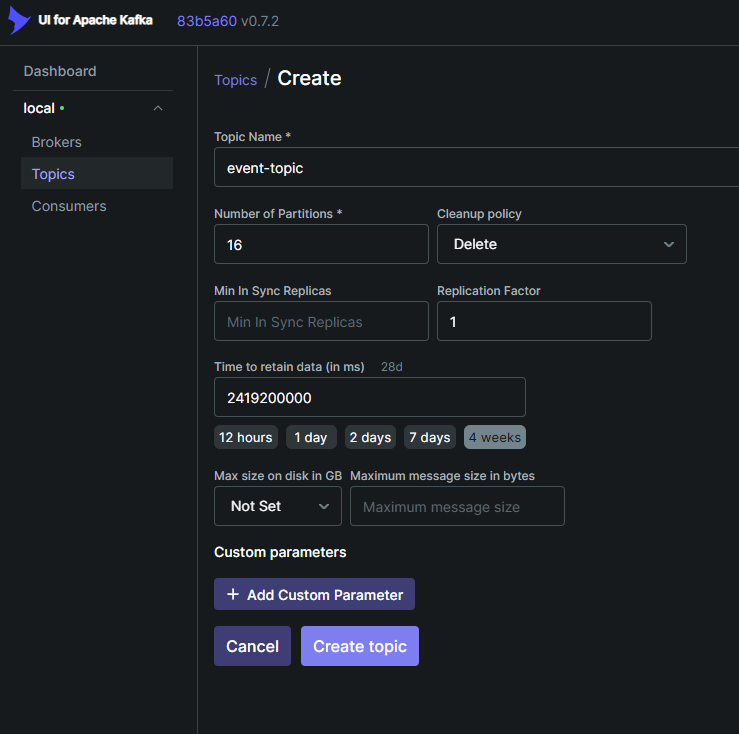
(2) alarm-manager를 여러 개 띄우기
여러 개 실행하기 전에 반드시 같은 application.id (group.id)를 사용해야 한다. 다른 아이디를 사용할 경우 서로 다른 알람 매니저로 여겨져 메시지가 중복 처리 될 수 있다.
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "alarm-manager-app");
상단 메뉴 화살표 > Edit Configuration

Copy Configuration

각 이름만 다르게 설정

modify options > Allow multiple instances

알람 매니저를 여러 개 실행할 수 있다.

AlarmManager.java 전체 코드
@Slf4j
public class AlarmManagerApp {
public static void main(String[] args) {
// 1. Kafka Streams 설정을 위한 Properties 생성
Properties props = new Properties();
// application.id
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "alarm-manager-app");
// bootstrap.servers
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9093");
// 상태 저장소 디렉토리
props.put(StreamsConfig.STATE_DIR_CONFIG, "C:/Users/puezn/kafka/kafka-streams-state");
// key/value serde 설정 등
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// (선택) 에러 로그 보기 쉽게 하기 위해 record 캐싱 끔
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, "0");
// commit 주기 짧게 - 1초 마다 커밋
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000);
// offset 설정
props.put(StreamsConfig.consumerPrefix(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG), "earliest");
// exactly-once 처리 모드
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE_V2);
// batch 처리 (메시지 묶어서 처리) - 한 번에 최대 100건 처리
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 100);
// 2. 알람 발생 조건을 저장할 Map 초기화
Map<String, AlarmCondition> alarmConditions = new ConcurrentHashMap<>();
/*
alarmConditions.put("login_fail", new AlarmCondition(
"login_fail", 5.0, ">=", 3, 1
));
*/
// 3. StreamsBuilder 생성
StreamsBuilder builder = new StreamsBuilder();
// 4. alarm-condition 토픽 구독 (조건 업데이트 수신)
// alarm-condition 메시지를 받아서 JSON 파싱
ObjectMapper objectMapper = new ObjectMapper();
KStream<String, String> conditionStream = builder.stream("alarm-condition");
// Map<String, AlarmCondition> 형태로 조건 저장 (기존 조건 갱신 포함)
conditionStream
.peek((key, value) -> log.warn("[조건 수신] key: " + key + ", value: " + value))
.foreach((key, value) -> {
try {
// 메시지를 Map으로 파싱
Map<String, Object> conditionData = objectMapper.readValue(value, Map.class);
String metricKey = (String) conditionData.get("metric_key");
double threshold = Double.parseDouble(conditionData.get("threshold_value").toString());
String operator = (String) conditionData.get("condition_operator");
int severity = Integer.parseInt(conditionData.get("severity").toString());
int category = Integer.parseInt(conditionData.get("category").toString());
// Map에 조건 저장 또는 갱신
alarmConditions.put(metricKey, new AlarmCondition(metricKey, threshold, operator, severity, category));
log.warn("[조건 갱신] metric_key: " + metricKey);
} catch (Exception e) {
log.warn("alarm-condition 파싱 실패: " + e.getMessage());
}
});
// 5. event-topic 구독 (이벤트 수신)
KStream<String, String> eventStream = builder.stream("event-topic");
eventStream
.peek((key, value) -> log.warn("[이벤트 수신] key: " + key + ", value: " + value))
.flatMapValues(value -> {
try {
Map<String, Object> eventData = objectMapper.readValue(value, Map.class);
String metricKey = (String) eventData.get("type");
int count = Integer.parseInt(eventData.get("count").toString());
// 조건 비교
if(alarmConditions.containsKey(metricKey)){
AlarmCondition condition = alarmConditions.get(metricKey);
if (compare(count, condition.thresholdValue, condition.operator)) {
// 조건 충족 시 → 추가 필드 붙여서 알람 전송
eventData.put("severity", condition.severity);
eventData.put("category", condition.category);
log.warn("[알람 판단됨] metric_key: " + metricKey + ", count: " + count);
return List.of(objectMapper.writeValueAsString(eventData)); // JSON 문자열로 다시 변환
}
}
} catch (Exception e) {
log.warn("event-message 파싱 실패: " + e.getMessage());
}
return List.of(); // 빈 리스트 반환
})
// 6. 조건 비교 결과에 따라 분기 조건 만족 시 → alarm-topic으로 전송
.peek((key, value) -> log.warn("알람 전송 예정 → {}", value))
.to("alarm-topic"); // alarm-topic으로 전송
// 조건 불만족 시: 그대로 event-log-topic으로 전송
eventStream
.filter((key, value) -> {
try {
Map<String, Object> eventData = objectMapper.readValue(value, Map.class);
String metricKey = (String) eventData.get("type");
int count = Integer.parseInt(eventData.get("count").toString());
if (alarmConditions.containsKey(metricKey)) {
AlarmCondition condition = alarmConditions.get(metricKey);
return !compare(count, condition.thresholdValue, condition.operator);
}
} catch (Exception e) {
return true; // 파싱 실패 메시지는 로그로 보냄
}
return true; // 조건 없음도 로그로 보냄
})
.peek((key, value) -> log.warn("로그 전송 예정 → {}", value))
.to("event-log-topic"); // event-log-topic으로 전송
// 7. KafkaStreams topology 빌드 및 시작
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
log.warn("AlarmManagerApp 실행 시작됨!");
// 8. shutdown hook 등록 (애플리케이션 종료 시 graceful shutdown)
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
log.warn("AlarmManagerApp 종료 중... KafkaStreams 종료 중...");
streams.close();
}));
}
private static boolean compare(int count, double threshold, String operator) {
return switch (operator) {
case ">" -> count > threshold;
case ">=" -> count >= threshold;
case "<" -> count < threshold;
case "<=" -> count <= threshold;
case "==" -> count == threshold;
case "!=" -> count != threshold;
default -> false;
};
}
}'Java' 카테고리의 다른 글
| Spring 기반 Kafka Producer-Consumer + Java 알람 매니저 (Kafka Streams 모듈화)로 실시간 알람 기능 구현 (0) | 2025.05.26 |
|---|---|
| Kafka 로컬 설치 및 Spring Boot에서 Kafka 연동하기 (0) | 2025.05.15 |
| DDD (Domain-Driven Design) 란? (0) | 2024.11.26 |
| [CBR] CBR (Case-Based Reasoning) 방식과 응용 (0) | 2024.11.12 |
| [Kafka] 카프카(Kafka) 기본 개념 (0) | 2024.11.12 |


